Overview
Vào ngày 28/5/2021, trên blog của Rails có thông báo về 1 tính năng mới đó là ActiveRecord Encryption.
ActiveRecord Encryption giúp encrypt attribute nào đó của model, và lưu vào DB dưới dạng mã hoá. Tính năng này được extract ra từ dự án HEY của Basecamp.
Hãy thử tìm hiểu xem tính năng này có gì thú vị.
Usage
Theo guide, đầu tiên chúng ta sẽ cần phải chạy câu lệnh sau
rails db:encryption:init
Rails sẽ cho ta 1 gợi ý là copy đống sau vào credentials. Ừ EDITOR=vim rails credentials:edit rồi copy paste thôi.
active_record_encryption:
primary_key: EGY8WhulUOXixybod7ZWwMIL68R9o5kC
deterministic_key: aPA5XyALhf75NNnMzaspW7akTfZp0lPY
key_derivation_salt: xEY0dt6TZcAMg52K7O84wYzkjvbA62Hz
Trong model, ta define attribute cần mã hoá như sau:
class Article < ApplicationRecord
encrypts :title
end
Rồi create/update model như bình thường
article = Article.create(title: "Encrypt it all!")
Và bùm, magic...
INSERT INTO `articles` (`title`) VALUES ('{\"p\":\"n7J0/ol+a7DRMeaE\",\"h\":{\"iv\":\"DXZMDWUKfp3bg/Yu\",\"at\":\"X1/YjMHbHD4talgF9dt61A==\"}}')
Vô hạn bối rối...
AES
Trước tiên ta hãy tìm hiểu về đống key mà Rails đã gen cho ta lúc đầu
active_record_encryption:
primary_key: EGY8WhulUOXixybod7ZWwMIL68R9o5kC
deterministic_key: aPA5XyALhf75NNnMzaspW7akTfZp0lPY
key_derivation_salt: xEY0dt6TZcAMg52K7O84wYzkjvbA62Hz
Rails gen ra đống trên như nào vậy?
puts <<~MSG
Add this entry to the credentials of the target environment:#{' '}
active_record_encryption:
primary_key: #{SecureRandom.alphanumeric(32)}
deterministic_key: #{SecureRandom.alphanumeric(32)}
key_derivation_salt: #{SecureRandom.alphanumeric(32)}
MSG
Nếu ai chưa biết thì đây là standard lib của Ruby, đơn thuần là... random mà thôi =))
Thế đống key này để làm gì? Ở mục Setup của guide, Rails cũng đã gợi ý cho ta, đống này dùng cho AES.
this will be used to derive the AES 32 bytes key
Vậy AES là cái khỉ mốc gì? Theo wiki, AES là viết tắt của Advanced Encryption Standard. Hay còn được biết đến với cái tên Rijndael. AES là 1 chuẩn mã hoá, sử dụng symmetric encryption. AES rất phổ biến ngày nay.
Thế bất nào mà lại đẻ ra thêm nhiều thuật ngữ hại não hơn vậy =)) Cứ từ từ rồi khoai sẽ nhừ, chúng ta sẽ tìm hiểu tiếp.
Trước hết thì, thế nào là mã hoá? Ví dụ như ở 1 diễn đàn nào đó người ta share nhau hoàng thuỳ link bằng đống kí tự này
68747470733A2F2F7777772E676F6F676C652E636F6D2E766E2F
thay vì huỵch toẹt ra là một đường link đồi truỵ nào đó. Nhưng do việc giải mã quá đơn giản, cụ thể là dùng mã HEX, nên đây chỉ là encode/decode sang 1 dạng dữ liệu khác mà thôi, và việc chuyển đổi thường khá nhanh. Các bạn có thể vào đây đây để decode chuỗi huyền bí trên.
Còn encrypt và decrypt dùng trong cryptography nó ở 1 tầm cao khác. Thông thường sẽ có thêm 1 key (hoặc 1 cặp key public/private). Khi đó input sẽ là key + data. Và output sẽ là 1 chuỗi nào đó, chuỗi này cực kì khó để giải mã nếu không nắm trong tay key. Thông thường thì phải cho chạy thuật toán vét cạn - tức là thử từng key một, và việc này cần đến hàng triệu năm đối với cả siêu máy tính.
- Với thuật toán dùng 1 key cho cả việc encrypt lẫn decrypt thì sẽ được gọi là symmetric encryption
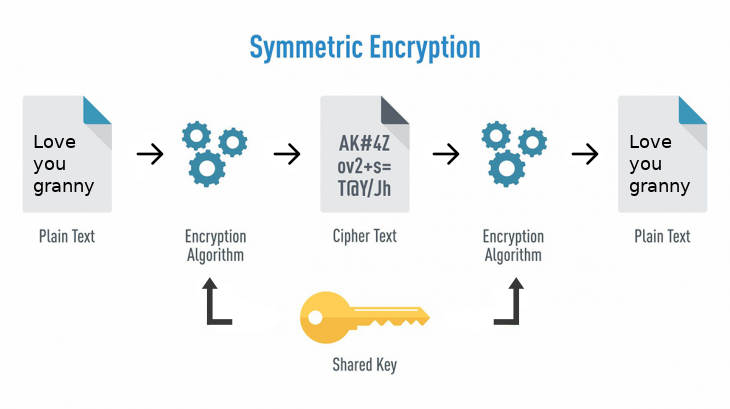
- Thuật toán dùng 1 cặp key, trong đó public key để mã hoá, còn private key để giải mã, được gọi là asymmetric encryption
Quay lại với AES, nó dùng symmetric, nên sẽ dùng 1 key cho cả việc mã hoá lẫn giải mã. AES key có độ dài là 128, 192, hoặc 256 bit. Tuỳ vào độ dài key nó sẽ có tên khác nhau AES-128, AES-192, AES-256. Key càng dài thì việc xử lý càng lâu, nhưng đổi lại càng bảo mật hơn. Mặc định Rails sử dụng key có độ d�ài 256 bit (32 bytes)
CIPHER_TYPE = "aes-256-gcm"
Về việc làm thế nào để AES mã hoá/giải mã thì mình sẽ không đề cập tại đây vì mình cũng không có hiểu mấy =)), nếu ai muốn tìm hiểu thêm có thể xem link này, hoặc gúc gồ ~~. Ở dưới là bản preview, trông cái thuật toán nó nôm na như sau
AES sẽ chia nhỏ input thành từng block để xử lý
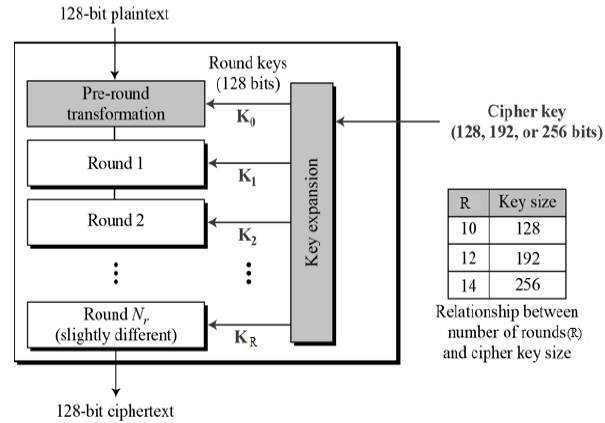
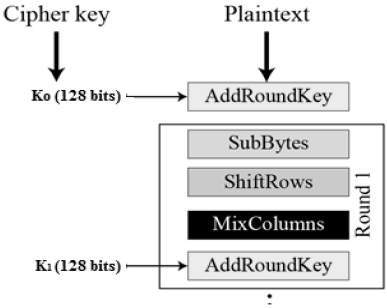
Cơ mà chỉ quan tâm là một chuỗi đầu vào + 1 key, đi qua đống black magic rồi trở thành 1 chuỗi bảo mật siêu hạng là quá đủ cho một cuộc tình rồi.
À mà nhìn cái constant Rails define ở trên kia, lại có thêm cái gì ở cuối chuỗi thế nhỉ. gcm???? Bối rối again.
GCM
GCM là viết tắt của Galois/Counter Mode... Nghe xong hiểu chết liền .__. Mò thử xem nào!
Như tên gọi của nó, GCM là một mode trong symmetric encryption, kết hợp của Counter Mode và Galois Mode, dùng cho mã hoá dạng khối (block). Vậy thì AES đi với GCM là chuẩn bài rồi nhỉ.
Ngoài GCM ra còn các mode khác như CCM, SIV, ...vân vân mây mây. Các bạn có thể xem thêm tại đây
Trước tiên ta hãy bắt đầu từ mode, từ này nằm trong Mode of Operation. Các mode sẽ được apply trên từng block data (như đã nói ở trên thì AES chia data thành các block nhỏ và mã hoá), giúp cho output của việc mã hoá block bảo mật hơn.
Counter mode sử dụng 1 số integer làm counter, qua từng block counter sẽ tăng lên 1. Ở mỗi block, số này sẽ được mã hoá cùng với data để có được output bảo mật hơn.
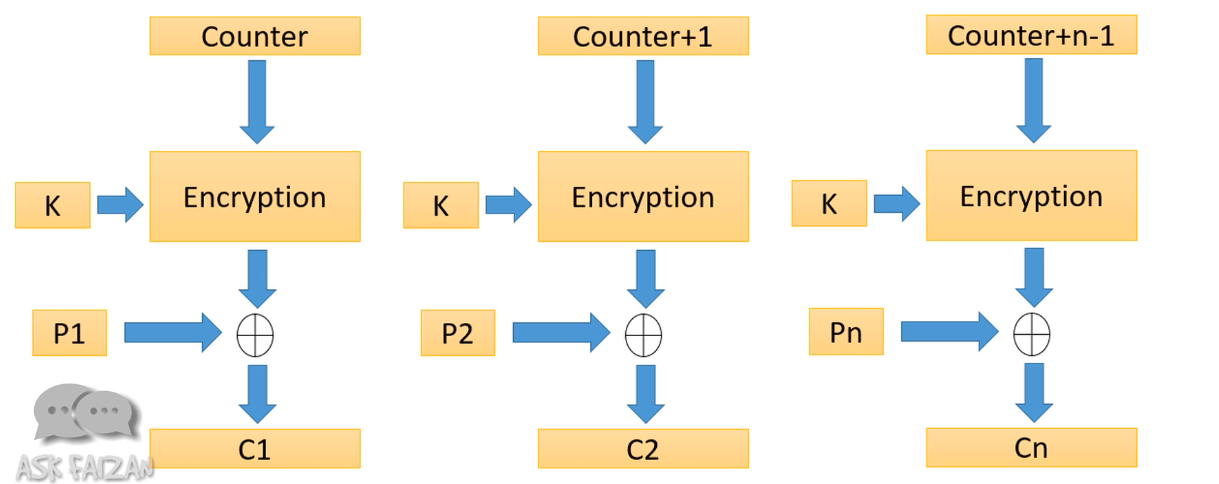
Galois Mode là một authentication mode. Galois Mode giúp đảm bảo rằng cipher output của ta không bị chỉnh sửa bởi một bên thứ 3. Hoạt động như nào thì mình chịu à =))
Kết hợp 2 mode trên và ta có GCM, giúp thuật toán mã hoá của ta bảo mật hơn, đồng thời đảm bảo được tính toàn vẹn của dữ liệu.
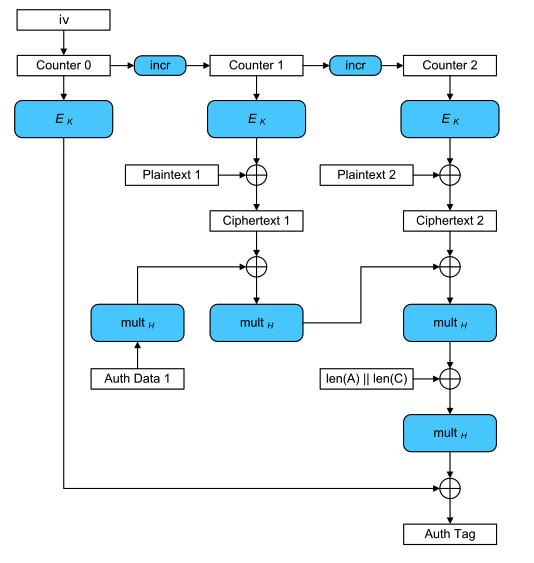
Bên trên là giải thích sơ qua về thuật toán mã hoá mà Rails sử dụng, nếu có sai sót thì cũng đừng gạch đá tội mình =))
AES-256-GCM meets Rails
Encryption Key
active_record_encryption:
primary_key: EGY8WhulUOXixybod7ZWwMIL68R9o5kC
deterministic_key: aPA5XyALhf75NNnMzaspW7akTfZp0lPY
key_derivation_salt: xEY0dt6TZcAMg52K7O84wYzkjvbA62Hz
Quay trở lại với đống key, hãy cùng mò code đáy bể xem chúng dẫn ta tới đâu :v
# https://github.com/rails/rails/blob/9c091b4fd378df515c4c31b85bb6a968463a1d82/activerecord/lib/active_record/railtie.rb#L313-L317
ActiveRecord::Encryption.configure \
primary_key: app.credentials.dig(:active_record_encryption, :primary_key),
deterministic_key: app.credentials.dig(:active_record_encryption, :deterministic_key),
key_derivation_salt: app.credentials.dig(:active_record_encryption, :key_derivation_salt),
**config.active_record.encryption
# https://github.com/rails/rails/blob/9c091b4fd378df515c4c31b85bb6a968463a1d82/activerecord/lib/active_record/encryption/configurable.rb#L20-L33
def configure(primary_key:, deterministic_key:, key_derivation_salt:, **properties)
config.primary_key = primary_key
config.deterministic_key = deterministic_key
config.key_derivation_salt = key_derivation_salt
context.key_provider = ActiveRecord::Encryption::DerivedSecretKeyProvider.new(primary_key)
end
# https://github.com/rails/rails/blob/9c091b4fd378df515c4c31b85bb6a968463a1d82/activerecord/lib/active_record/encryption/derived_secret_key_provider.rb#L7-L9
def initialize(passwords)
super(Array(passwords).collect { |password| Key.derive_from(password) })
end
Xem tiếp class Key có gì nào.
# https://github.com/rails/rails/blob/9c091b4fd378df515c4c31b85bb6a968463a1d82/activerecord/lib/active_record/encryption/key.rb#L10-L26
class Key
def initialize(secret)
@secret = secret
@public_tags = Properties.new
end
def self.derive_from(password)
secret = ActiveRecord::Encryption.key_generator.derive_key_from(password)
ActiveRecord::Encryption::Key.new(secret)
end
end
# https://github.com/rails/rails/blob/9c091b4fd378df515c4c31b85bb6a968463a1d82/activerecord/lib/active_record/encryption/key_generator.rb#L32-L34
def derive_key_from(password, length: key_length)
ActiveSupport::KeyGenerator.new(password).generate_key(ActiveRecord::Encryption.config.key_derivation_salt, length)
end
Như vậy, 2 trong số 3 thanh niên của ta đã bị lộ mặt:
primary_keyđóng vai trò làpasswordparam củaActiveSupport::KeyGenerator.newkey_derivation_saltđóng vai trò là tham số thứ nhất củaActiveSupport::KeyGenerator#generate_key
Hãy check tiếp ActiveSupport::KeyGenerator
# https://github.com/rails/rails/blob/9c091b4fd378df515c4c31b85bb6a968463a1d82/activesupport/lib/active_support/key_generator.rb#L26-L41
def initialize(secret, options = {})
@secret = secret
@iterations = options[:iterations] || 2**16
@hash_digest_class = options[:hash_digest_class] || self.class.hash_digest_class
end
def generate_key(salt, key_size = 64)
OpenSSL::PKCS5.pbkdf2_hmac(@secret, salt, @iterations, key_size, @hash_digest_class.new)
end
Qua hết wrapper của Rails rồi, giờ ta phải mò vào docs của Ruby thôi.
Theo docs, docs lại bảo hàm này giờ đổi tên thành OpenSSL::KDF.pbkdf2_hmac mất rồi... Ờ thì lại mò vào xem. Nôm na hàm này sẽ tạo ra 1 cipher key dùng cho việc mã hoá.
Tại đây, ta có thể kết luận key mã hoá mà Rails dùng có:
passphrase:primary_keysalt:key_derivation_saltiterations: 2^16key_len: độ dài key 32 bytesdigest: hash algorithm SHA-1
Hãy cùng test qua cái key này xem
require 'openssl'
cipher = OpenSSL::Cipher.new('aes-256-gcm')
cipher.encrypt
iv = cipher.random_iv
pwd = 'EGY8WhulUOXixybod7ZWwMIL68R9o5kC'
salt = 'xEY0dt6TZcAMg52K7O84wYzkjvbA62Hz'
iter = 2**16
key_len = OpenSSL::Cipher.new("aes-256-gcm").key_len
digest = OpenSSL::Digest.new('SHA1')
key = OpenSSL::PKCS5.pbkdf2_hmac(pwd, salt, iter, key_len, digest)
cipher.key = key
encrypted = cipher.update "hello"
encrypted << cipher.final # => "\xB2#\x10\xE7n"
cipher.decrypt
cipher.iv = iv
decrypted = cipher.update(encrypted) # => "hello"
Sau bao nhiêu vất vả thì cũng tìm được cái key =)) Vậy quá trình mã hoá như thế nào? Lại mò tiếp .__.
Encryption Process
Hãy cùng bắt đầu từ việc khai báo trong model
class Article < ApplicationRecord
encrypts :title
end
Rồi cùng tìm xem ApplicationRecord.encrypts nó làm trò gì nào